About the Authors
Dr. Fabian Niemann (Partner, Bird & Bird Germany) is an expert in technology, copyright and data protection law. His ambition is to provide the best and most suitable advice to clients and to guide them through their technology and data transactions and their IT, digitalisation and data projects, contracts and compliance in a pragmatic, solution-driven and innovative manner. He is co-head of B&B’s international Technology & Communications Group and head of B&B’s German Data Protection Group.
Friedemann Lutz (Director, OXYGY) has supported numerous Management Teams to run demanding initiatives to drive data and digitally driven change, translate ambitious strategic goals into reality and reach and sustain better business results. Many times he has facilitated the discovery of data driven digital, innovative and customer-centric solutions. He is leading the Operating Model Transformation Practice at OXYGY, the consulting arm of Bird & Bird.
1. The Data is already there: Companies need data strategies to exploit it
Data is one of the key resources of any organization. As a resource, it is fuelling many breakthrough innovations and successes, such as using AI to support drug development (and dramatically reduce development lead times), or to provide anticipatory shipments to retail customers. The good news is, there is lots of data available, inside and outside your organization. It is clearly an abundant resource as such. However, it is difficult to make the data you need to build your future available, and to transform it into value, creating insights:
- Even critical data is often incomplete (e.g., customer contact data collected by sales reps).
- A lot of different data sets have been used for different purposes in the past, but many are not compatible and therefore cannot be linked.
- There is no overview of what data can be reused for other purposes as most companies have no clear overview as to:
- the exact circumstances in which personal data has been collected, with what communication and which consents of the data subjects, and
- regulatory restrictions applicable to some or all data sets and contractual obligations we have for each data set towards business partners, customers and suppliers.
- Companies often do not exactly know how they want to use the data and thus which data they actually need.
These limiting factors can be addressed. While there are still many difficult legal, technical and cultural hurdles regarding data sharing in Europe (which needs to be overcome to combat challenges such as climate change, pandemics and global diseases, sustainable and sufficient global nutrition, and to remain competitive in future technologies like AI), the difficulties companies face to explore their data can be solved much more easily. However, this needs the right approach.
Consider these 2 examples: In an insurance company, every business line is working on improving their data quality & completeness and each also sees the benefits of this. But when it comes to x-sell, data from different business lines can only be matched with high effort and even the simplest value creation from data, such as understanding when a customer may have additional needs, becomes very difficult.
On the other hand, look at a bank which created analytics both to predict financial needs of their customers and to better understand and manage credit risks. They started with data, which customers generated themselves when banking with them, and then encouraged them to become engaged in data rich transactions. They tripled cross-sell rates and reduced credit losses. Additionally, they built an ecosystem that generates additional data from sales transactions, enabling a better understanding of customer preferences and the opportunity to propose ever better tailored solutions.
2. Legal Background
Data is complex from a legal perspective. Other than specific forms of data (content) such as software, movies or music (which are protected under copyrights) and other than the carrier data is stored on (which enjoys physical property protection), data as such is not generally protected under law in Europe or in any major market elsewhere.
There is a lot of discussion about creating a “general data right”, but so far it does not exist and it is unlikely to come into existence in the near future, if ever. That does not, however, mean that the data which a company possesses, is able to access, or is able to obtain can always be freely used. This is because some forms of data can be protected under copyright (see above) and, more important in an industrial context, use of data may be legally restricted, in particular under data protection, data base or trade secret laws.
If data qualifies as personal data under the European General Data Protection Regulation (“GDPR”), any use of it is governed by strict regime of the GDPR (and similar regimes popping up more and more in other regions of the world). Data protection is seen as a showstopper by some companies which want to exploit their data, while other companies ignore data protection when exploiting their data, in particular industrial data which they think is not covered by data protection. Both approaches are wrong. Data protection laws apply in many more scenarios than you might think, but also allow more use cases than you may think – provided you do it right and are willing to avoid always following the most conservative legal interpretation.
Next to data protection, data base rights (existing in the EU and a few other countries, but not in most other party of the world, e.g. the US), trade secret laws, and contractual restrictions may be applicable to certain data and may need to be observed. To do so you need to know how or from whom you obtained the data, under which terms, and for which purposes.
3. Technical inventory: Which data do I have?
The above-mentioned clearly shows the need for companies to have knowledge on and about the data they have. Such knowledge must be obtained, but it must be obtained in a smart manner, with at least an initial strategy in mind. Many organizations start their journey towards the data driven future with a general big data inventory, trying to create a large catalogue of all the data they have in all the different departments and locations. We believe this is a good recipe for losing a lot of time and money on outputs with too little business value. Therefore, we recommend starting with a different question: What data would be most valuable to have or to acquire? Instead of a catalogue of what we have in stock, the data journey should start with a first prioritized shopping list of what we need or would like to have.
This of course is more difficult to create, if you do not know what you want and can do with data for your business. Usually, it is not necessarily a full data strategy which is needed here. But for sure, it is worth finding out and making up your mind. And once you know, you can do a prioritized data inventory and check how much of that data:
- is already available and ready to use.
- is somewhere but may be unstructured and difficult to work with and analyse.
- is not available but can be collected internally.
- can be sourced externally with existing business partners or ecosystems.
- must be sourced externally with new business partners or ecosystems, may be even in a very competitive context (with other competitors looking for the same data)
In practice, this is an iterative process: Starting with the more strategic question of what value we can deliver to our customers with which data, then checking how much of this data is available (gap analysis) , understanding what data we have available, which additional opportunities may arise, and finally reviewing the strategic question of what we can do and want to do with it.
For your data inventory, these are the typical questions you will want to answer.
- What data do we currently have?
- Where does it come from / sources
- Category of data? Does it include personal information and, if so, which data subjects are concerned (employees, customers, etc)?
- Which attributes?
- Where is it located?
- What is the level of quality of the data? (e.g. Completeness, Accuracy)
- What is the level of technical readiness for use? (Central index points (required to link different data sets), Alignment of different data sets (definitions, scope of attributes, etc.))
- What is the legal readiness for use, especially for personal data?
- Under which legal circumstances was the data collected?
- Is the data subject to license terms or contractual restrictions?
- What purpose was it collected for?
- What consents do we have?
- What contractual obligations and limitations do we have?
- In addition, you may define business driven additional questions to be analyzed, e.g. existing contractual obligations towards business partners and clients.
A typical roadmap towards a valuable data inventory looks like this:
- Create your initial data strategy, including a basic understanding of the legal framework
- Based on the strategy, define high level target data map – focus on what is important!
- Review existing data inventories
- Map existing data against target map
- Reflect the regulatory landscape and legal restrictions
- Test and assess technical readiness and identify gaps and how to close them
- Assess legal readiness and identify gaps and how to close them
- Create a summary and develop a roadmap for improvement
- Undertake your data inventory
Hints & Tips for creating a valuable data inventory
- Start with a clear idea of what data your organization is likely to use for what. This does not have to be a full data strategy but helps to focus the initiative on the right priorities and to explain to all people involved why this is important
- Work with very clear definitions for meta data and train all people involved very well
- Take time to talk to those who
- Collect or collected the data, to gain insights about quality issues that may result from certain data collection practices
- Work with the different current data sets (e.g. for data analysis), to gain insights of typical gaps and issues and how they have been handled
4. Regulatory inventory: What may I do and how do I protect myself?
The opening remarks under 1. and 2. above clearly demonstrate the need to understand the limitations which laws may impose on the collection and exploitation of data. For compliance reasons, a data inventory therefore should also always include a regulatory inventory. But it is not only about compliance. Checking the regulatory background is an essential part of a meaningful initial data strategy. You need to find out which data can be exploited in a legal manner as there may be little or no need to invest efforts in a data inventory regarding data which can’t be exploited. Equally it is important for the data strategy to know how you can and should use and protect the data you possess. The most well-known restrictive law is the GDPR. As mentioned, the GDPR applies more often than many people think, but it also provides more flexibility than some conservative lawyers say.
Six GDPR key take-aways to consider when developing your data strategy, and when undertaking a regulatory inventory and a data inventory:
- The definition of “personal data” under the GDPR is very broad, and accordingly the application of the data protection laws is: Machine and device numbers and usage data can be seen as personal data if they allow conclusions to the user of the machines and devices; business contact data is personal data; pseudonyms are personal data. Only real anonymous data is no personal data, but the threshold for proper anonymisation is high and will likely become higher in days of quantum computing.
- Personal data which a company legitimately possesses and uses for its original purposes cannot be freely used for other purposes, such as product and process improvement, BI or sales & marketing. Every new use needs a new legal justification under the GDPR and hence a legal assessment.
- The GDPR acknowledges the benefits of data analytics and provides for a number of legal justifications which allow such use of data in many instances (e.g. based on legitimate interests or for research purposes), but not every (internal or external) use is allowed and different kinds of data may need to be distinguished (e.g. health data enjoy a higher degree of protection than address data). So, you need to build a view which data you want to use for which purposes.
- It is not correct that so-called “sensitive data” (such as health data) cannot be subject to data analytics or machine learning use cases, but it is more restricted and more difficult.
- Don’t forget that data protection protects the individual data subject, i.e. the natural person the respective information is about. It is never about the company which possess or “owns” the data. Hence, as a company, you can’t rely on a license or business partner’s consent when you want to use personal data. And you cannot build your strategy around the assumption that you control and decide on all data use cases alone. The data subject is always part of the game.
- The level of protection and the details set out in national laws vary internationally. What may be legitimate in one country, may not be legal in another country. For example, the definition of “personal data” in the US (often called there “PII” /”Personal Identifiable Information”) is less broad; a use case which does not trigger the application of US data protection laws may trigger the application of the GDPR.
This is not only the only form of data protection to consider. Data which constitute an “original work” (which usually is understood as a work which is the expression of creativity of a human being) is protected by copyright. Examples are music, movies, software, photographs, literature, art, but also small text works and drawings may constitute a work protected under copyright if it has sufficient originality. When you use only industrial machine data, copyright is not relevant, but pay attention if you use photographs or drawings – there may be limitations under copyright, so you need to know the actual content of the data. An interesting, as yet unsolved question is whether AI can create a copyright protected “original work”.
Data as such is not protected. This also applies to data in a database. However, the database can be protected under copyright or database rights and extracting / using data from a database may infringe the rights in the database. Whether using data from a database infringes the rights in the database in practice depends on the actual use cases, in particular the amount of data used/extracted, the competitive situation and the owner of the database (public versus private, EU versus non EU). There are lots of nuances to bear in mind, but the key message is that a user of data from a database needs to check whether it requires a license in the database to use the data; and the owner of a database cannot rely upon database rights providing full protection. It may need further contractual and technical means.
As with all information, data can constitute a trade secret protected by trade secret laws. If this is the case, the data may not be freely exploited by third parties without the consent of the trade secret owner. In reverse, the trade secret owner should consider that exploiting its data assets by way of data sharing, licensing, or pooling may destroy the “confidentiality” of the information and, as a consequence, end the protection as a “trade secret”.
The above only provides a rough summary of the legal evaluations being part of a regulatory inventory. For a meaningful data inventory and data strategy the above key legal areas need to be evaluated further. In addition, sector specific regulations may include further rules and limitations and must be evaluated, e.g. in the public sector, heath sector, defence sector or financial services sector. Finally, cross border data transfers may trigger additional issues under data protection and data localisation laws, in particular if data shall leave regions with strict privacy regimes like the EU or countries with heavy data localisation laws such as Russia and China.
The regulatory inventory should help you to decide which information you obtain and which data you investigate in your data inventory, and it should enable you to answer in particular the following questions as part of your final data strategy.
Questions as part of your final data strategy.
- Which data may I legally collect, own, exploit, share (with whom) and otherwise use?
- How can I do this?
- Where can I do this?
- Which contributions (licenses, consents etc) do I need from a legal perspective, and which obligations do I create if I start using data for new purposes (e.g. informing data subjects)? Is all of this feasible?
- How is my data currently protected? What can and should I do to increase the protection?
- How do I roll out regulatory requirements and means to protect my data within my organisation?
- How do I keep up to date on regulations globally and ensure ongoing compliance and the best protection?
5. Data Strategy: What are my goals and opportunities – and how do I ensure the data needed is available.
A good data strategy is your entry ticket to data driven business models. The winning companies can:
- Fully utilize internal and external data to offer new/better products and services
- Widely use data driven decision making to better target customer and optimize internal processes
- Harvest big data business model: data user / data supplier / data facilitator
- Gain competitive advantage using technologies like machine learning, deep learning, enforced learning, blockchain
- Consciously manage their risks
- Effectively AND efficiently fulfil compliance requirements associated with data
With a well-developed and targeted data pool, the agility of working with data will increase and, for example, time to market will decrease for data driven innovations:
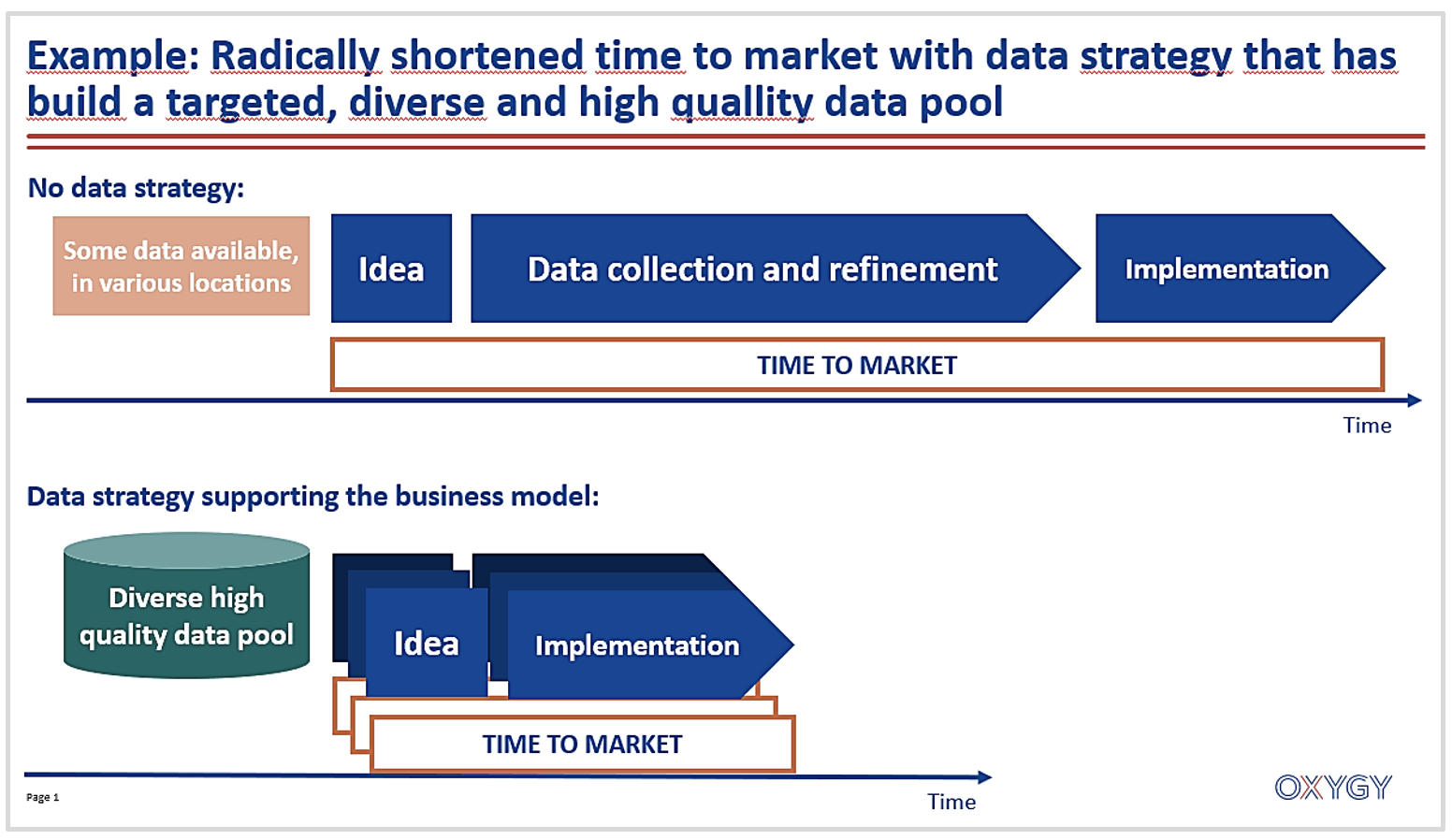
However, building the foundations for data success takes time, effort, and determination.
A good data strategy answers two main questions:
- How does data contribute to the overall business strategy?
- This question can also be addressed as part of the overall business strategy and the data strategy just builds on this. But without answering this question, it is impossible to build a sensible data strategy
- How to ensure the required data is available and we are able to extract the right conclusions?
- This question is about how to build and develop the right data pool needed.
Depending on the answer to the first question, and your gap analysis from your data inventory, a good data strategy should address points like:
- Where and how to source additional data? (internally, externally, data sharing, etc.)
- How to improve data quality?
- How to improve alignment between different data, so we can combine them?
- How to aggregate data?
- How to protect our ownership of data?
- How to ensure we know what data we have?
- What opportunities does our data have?
- How owns data and data integrity?
- How to ensure compliance with data protection, data retention and other requirements, without slowing down data driven innovation?
- How to align all functions working with data?
6. Create additional opportunities & reduce risks by a proper process
Undertaking a technical, regulatory and business inventory based on a data strategy are the cornerstones for a smart data inventory and subsequent use of data. It is the most efficient way to understand and document the data assets a company owns, and the ways to maximize its benefits and opportunities.
Often, companies only find out business opportunities after the inventory. You need an initial strategy for the inventory, but it is an iterative process – this is why the initial strategy is “initial” and evolving.
The inventory may not only reveal new business opportunities, but also ways to increase your data assets, and means to reduce risks and improve your legal situation, e.g. additional data sources you can and should use to refine your data treasure, needs to change the way you collect or store data (e.g. anonymisation for legal use), protocols (technical or legally/contractually) you have to follow when collecting, storing or using data, means to protect your data better etc.
Proper documentation of the processes and procedures is important, not only for your operations, but also to limit your legal risks. It limits your legal risks in a triple manner: first, by documentation you ensure that processes and procedures are indeed followed; second, documenting your data processing is a legal obligation in itself under the GDPR; and a proper documented process limits the risk of fines even if you fail – you thereby demonstrate a proper governance which is key for authorities when looking into data breaches or cases of excessive data use and misuse. A data inventory without a strategy and a proper management and process is therefore not only costly, inefficient and missing opportunities, but also creating legal risks – both when doing the inventory itself, and when later using the data.
7. Conclusion
The well-known saying ”data is the new oil” is truer than ever: sensors collecting data and connectivity are everywhere – M2M, 5G, machine learning and AI, the power of quantum computing – the era of data has just begun, and the opportunities for companies are endless.
On the other hand, the comparison with Oil is deeply misleading. Oil is a commodity, but a high-quality data pool is not. It is a highly bespoke asset that often takes years to develop. To exploit the opportunities and gain competitive edges, companies need to act and not react.
A comprehensive, meaningful, strategy-driven data inventory, undertaken wholistically is the first step to become a winner in the era of data. This is not a subsidiary matter but needs top management attention and support.
And you need an A-Team to do this: technical experts, legal experts, and business advisors.